How the H&G All-Time Index v2.0.0 is built, and how far you should trust it
A reproducibility appendix and methods record for the Honour and Glory All-Time Index, version 2.0.0.
This paper documents the shipped v2.0.0 public model. It is written for a reader who wants to know not only what the ranking says, but how it was produced, which established methods it rests on, where it is firm, and where it is deliberately cautious. The headline claim of v2.0.0 is narrow and testable: the rating fit is fully deterministic, and two independent cold rebuilds of the published pipeline produce a byte-identical board. That property, not any single placement, is what the version is for.
Prefer the same account without the technical apparatus? Read the plain-language companion. It covers the same ideas in plain terms. This formal version keeps the methods detail, the trade-offs and the references.
1. What v2.0.0 is
The All-Time Index orders the public top 1000 men's professional boxers on a fixed 0 to 100 scale. Underneath the display index sits a six-dimension model fitted from a Whole-History Rating of the recorded bout corpus, followed by a bounded Bayesian shrinkage prior. v2.0.0 keeps the v1.2 common-scale model, its validation suite, the Peak-form Elo posterior bands and the Data Confidence labels. It changes one thing in the fit and inherits a run of corrections accumulated since v1.2.3.
The board is score-neutral and rank-neutral against v1.2.3. No fighter changes position. The model scores are unchanged to rounding. The recomputed Peak-form Elo shifts by about half an Elo point on average across the field. The point of the release is reproducibility, and the rankings staying still under that change is a result worth stating plainly: making the fit deterministic did not move the order.
2. The methods, and the literature they rest on
The model is not a new invention. It assembles established rating methods, and it is worth naming them so a reader can check the lineage rather than take the result on trust.
The base object is a paired comparison. A bout is a contest between two fighters with a recorded result, and the statistical question is the same one posed by Bradley and Terry (1952): given a set of results, what latent strength for each competitor best explains who beat whom. The Elo system (Elo, 1978) is the dynamic, sequential answer most readers will know from chess, and it is the scale on which the Peak-form Elo rating in this product is reported.
The career rating profile that carries most weight in the model is not plain Elo, however. It is fitted with Whole-History Rating (Coulom, 2008), a Bayesian method that estimates a competitor's entire time-varying strength curve at once rather than updating a single number bout by bout. Whole-History Rating is the right tool here for two reasons. It uses the whole record of a career together, so a fighter is not penalised by the arbitrary order in which historical results happen to be processed, and it represents strength as a curve over time, which is what an all-time question actually needs: not a fighter's number today, but the shape of their career at its best and across its length.
On top of the fitted features sits a Bayesian shrinkage prior. Shrinkage is the long-established idea that an estimate from sparse evidence should be pulled towards a sensible reference, and that doing so reduces error on average (Efron and Morris, 1975; Gelman et al., 2013). In this model the reference is an external expert list and the amount of pull is bounded, as section 8 sets out.
The paired-comparison framing has a concrete shape in this data. The chart below draws every recorded bout between two ranked fighters as one line. It is the reason a cross-era comparison is a measurement rather than a guess: almost every ranked fighter in 130 years of records is joined to the rest through chains of real results.
The whole archive at once
Before any rating is worked out, the engine reads the full fight archive: 921,982 fights between 213,243 boxers, from 1880 to 2026. This picture is the whole graph at once: every boxer is a point, and every thread joins two boxers who really fought.
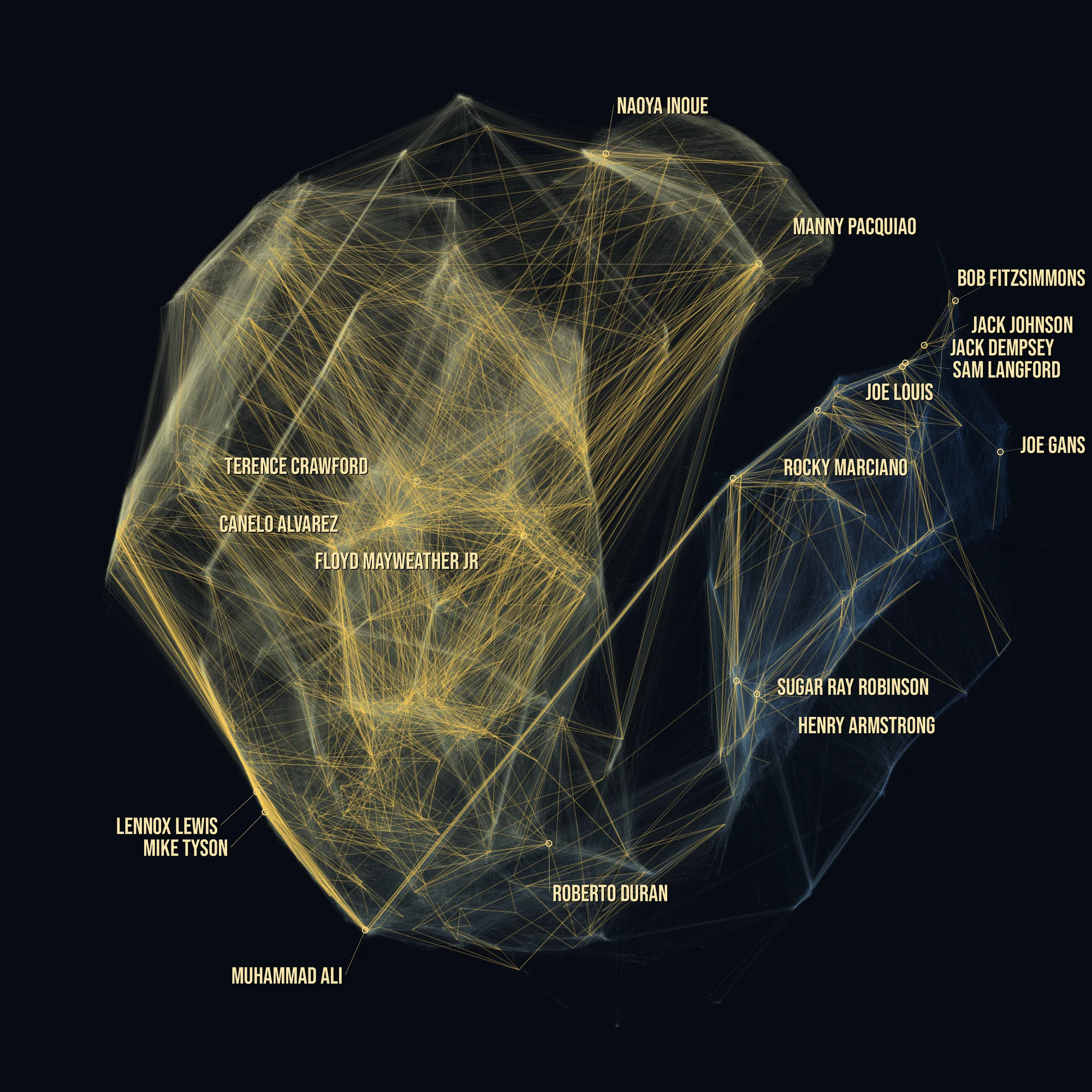
The layout pulls connected fighters together, so the shape you see is the structure of boxing itself. Colour is era: steel blue for the early decades, warm cream for the modern game. The gold running through everything is the 2,738 pairings between the 1,000 ranked fighters: the signal the rating pulls out of the mass, woven through the whole web. One fact the data surfaced on its own: Canelo Alvarez is the most connected fighter in the web, with 58 fights against other ranked names.

The same archive unrolled in time. Each fight is a thread at its year, joining the two careers that met that night: the bright band is each generation fighting itself, and the streaks above it are veterans crossing eras to meet the next wave. Gold is the ranked fighters again.
One web of real fights
We started from 1.36 million recorded bout rows. Between the 1,000 ranked fighters there are 4,157 real fights across 2,738 different match-ups. 974 of the ranked fighters faced at least one other ranked fighter, and 99 in every 100 of them connect into one web that stretches from 1896 to 2026. Every line below is a real fight.
This web is how the rating compares eras. A fighter from 1896 never met a fighter from 2026, but chains of real results join them, step by step, opponent by opponent.
Drawing the fight web, one moment.
Time runs left to right, from 1896 to 2026. Lighter weights sit near the top, heavier weights near the bottom. Bigger dots are higher scores. Drag to move around, pinch or scroll to zoom, and tap a dot to open that fighter's page.
3. The change at the centre: determinism through bout-merge order independence (#47)
Version 1 of the rating engine resolved repeated or near-duplicate bout records with a merge step whose result depended on processing order. The fit was then pinned to a single sealed draw so that the published board would not drift between runs. The pin held the output still, but it concealed a real property of the method: re-run from scratch, the underlying fit could land somewhere slightly different.
v2.0.0 replaces that step (internally tracked as change #47) with an order-independent, quality-based bout merge. Given the same corpus, the merged bout graph is now the same regardless of the order records arrive in, so the Whole-History Rating that follows is the same, and so is everything derived from it. The pin is gone because it is no longer needed.
The test of that claim is direct. Build the board cold, from the committed inputs, twice, on the shipped pipeline. Then compare.

The board is identical once the wall-clock generation stamp is set aside. The Peak-form sigma file and the yearly rating trajectory are byte-identical at the level of their SHA-256 digests (NIST, 2015). This is the scientific content of the release. A ranking you cannot reproduce is an opinion with a number attached. A ranking that rebuilds to the same bytes is a measurement, open to audit.
4. The reproducibility claim, stated precisely
It is easy to overclaim reproducibility, so the claim here is deliberately bounded.
The Python pipeline is self-contained except for the system Python interpreter and its standard library. The board, the sigma file, the yearly trajectory, and the rendered ranking pages are byte-identical across two cold runs. The render's self-containment is inferred rather than separately traced: the render reads inputs that live inside the pack, and it was shown to be deterministic by rebuilding it, not by tracing every file it opens. The board is reproducible from the pack given a compatible Python environment.
What this paper does not claim: that the entire website reproduces, or that the build is fully hermetic. The claim is the board and its pages, given compatible Python. That boundary is the point of stating it.
5. How the model earned trust: the audit cycle
The model was not declared correct. It was put through repeated adversarial audit rounds and revised where it failed. The structure of those rounds matters as much as their findings, because a defect found once and guarded against is worth more than a defect merely fixed.
The data-integrity round checked that the corpus the model reads matches a pinned fingerprint before any fit runs, so a drifted input cannot quietly change the board. The identity-resolution round hunted a class of six defect types in which one fighter can be split across transliterations or near-duplicate records, or two fighters merged by a shared name. The title-billing round examined where pre-1962 "world" billing had been credited as a modern undisputed or lineal title, and gated that credit on a reign reference rather than on the billing word. A membership round interrogated which fighters belong in the public 1000 at all.
Each round left a guard behind, so the same defect cannot return unnoticed. These guards run at build time and fail the build on regression, which is the difference between a model that was once correct and a model that stays correct. The board you read is the board that survived those rounds, which is a different and stronger statement than the board we believe is right.
This release also inherits a documented development process rather than a single author's judgement. The version line was planned as scoped, prioritised work: a labelling and transparency layer, a data-correctness layer, a feature-structure refactor, a formalisation of the prior, a validation and uncertainty layer, and a deferred research track for stoppage signals. That plan was put to an independent adversarial review before adoption, and the sequencing it produced (correctness before refactor, refactor before prior, prior before validation) is the order this work followed.
6. Active years as a first-class quantity
Many era-relative measures depend on when a fighter was active, and careless year handling distorts them. v2 treats the active-year span as a quantity to be derived, not assumed. First and last active years are taken from the merged bout records, and a span correction was applied across the field where the previous handling had been loose. Getting this right matters because the model conditions evidence weight on era and on how recently a career ended, so a wrong span feeds a wrong confidence. A known earlier defect of this class, a two-digit-year parse that pushed a turn-of-the-century career into the wrong century, is now covered by a named regression case.
7. The colour line, recognised and handled with care
A history of the sport that ignored the colour line would be dishonest, and one that scored across it without comment would be careless. The data carries an explicit colour-line recognition layer with curated provenance. It neither erases the segregation-era barrier nor treats a missing cross-line bout as if it were a settled comparison. Where the record is shaped by who a fighter was permitted to face, the system states the pattern and stops there. It does not convert a historical barrier into a rating adjustment, and it does not impute motive to individuals from an absence of bouts.
8. The expert prior, stated modestly
The model includes a Bayesian shrinkage prior. It is worth being exact about what that prior is, because it would be easy to dress it up.
The prior is the International Boxing Research Organization 2019 all-time pound-for-pound ranking (IBRO, 2019). It is one organisation's list. It is not an averaged consensus of expert panels, and this paper does not present it as one. Its influence is bounded by construction: it is worth four equivalent evidence units, which means it shrinks a fighter's score towards the reference position only as far as four bouts' worth of evidence would, and far less once a real career of recorded bouts is present. The shrinkage follows the standard logic that sparse estimates gain from being pulled towards a reference (Efron and Morris, 1975). The Ring magazine, the Transnational Boxing Rankings Board and ESPN all-time lists are held as comparators for validation, not blended into the prior.

9. The six-feature model
The six fitted weights sit on common-scaled features, so the weights operate on comparable variance rather than on raw units of different size. Broadly, the dimensions are: the career rating profile from the Whole-History Rating fit, which carries the most weight; external elite-win and honours evidence; contemporary ranking evidence; record quality and career depth; title evidence; and a source-confidence dimension that reflects how complete the underlying evidence is. The weights sum to one. The prior of section 8 is an added scoring transform on top of these, not a seventh weight, which keeps the feature contributions and the prior contribution separable and separately auditable.
10. The two scales, and why the top peak is not number one
A frequent confusion is worth heading off. The 0 to 100 All-Time Index that orders the board is not the same as the Peak-form Elo rating shown on the rating curve. They measure different things and they are on different scales.
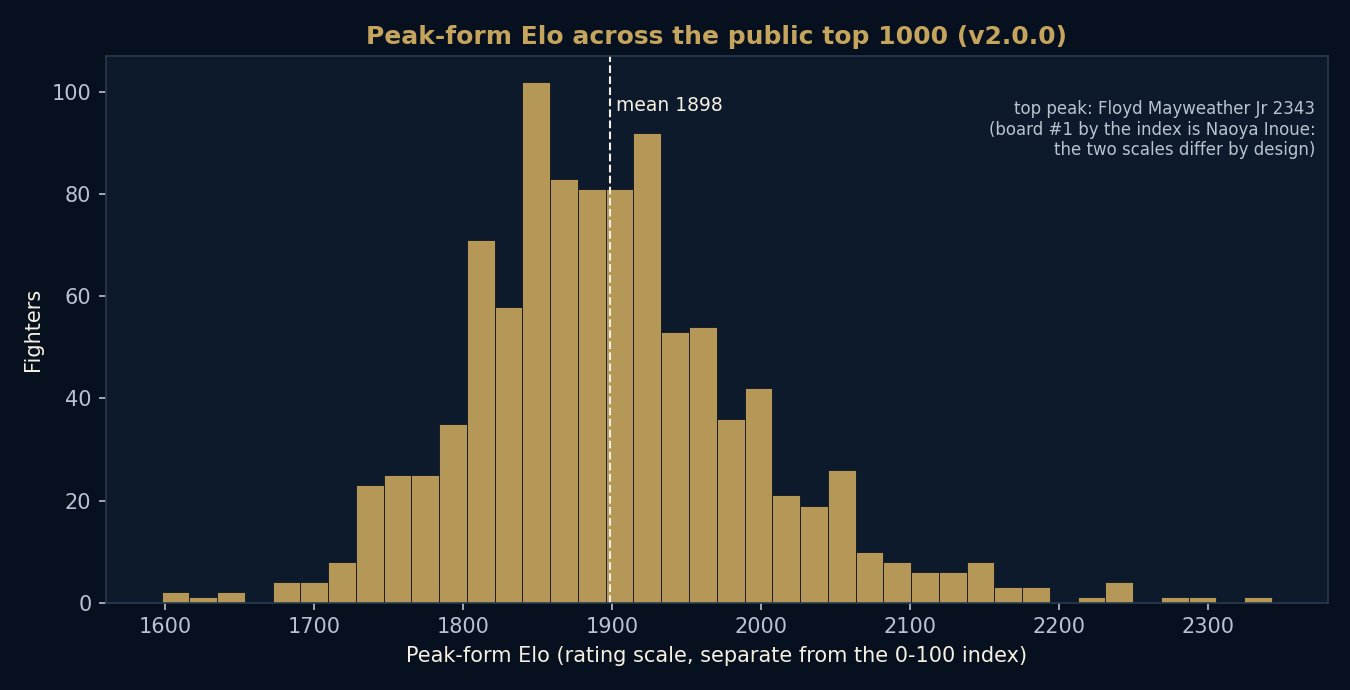
The highest Peak-form Elo in the field belongs to Floyd Mayweather Jr. The board's number one by the index is Naoya Inoue. Both statements are correct at once, because peak rating height and all-time index position are answering different questions. The Index blends a whole career, its opposition, its honours and its length; the Peak-form Elo reports the single highest point of the fitted curve. A reader who spots the mismatch and is not told why will reasonably lose trust, so the paper states it rather than hiding it.
11. Coverage, and the censoring it really shows
Older and thinner records carry more uncertainty, and the model needs a measure of how complete the evidence is for each fighter. Coverage is defined as the share of a fighter's known opponent bouts that the corpus has actually captured, computed from committed counts.
An earlier draft of this paper read coverage as a flat value near 0.75 for almost everyone and discussed it as a censoring artefact. That was a bug in the input, not a fact about the sport. The corrected coverage is a real gradient.
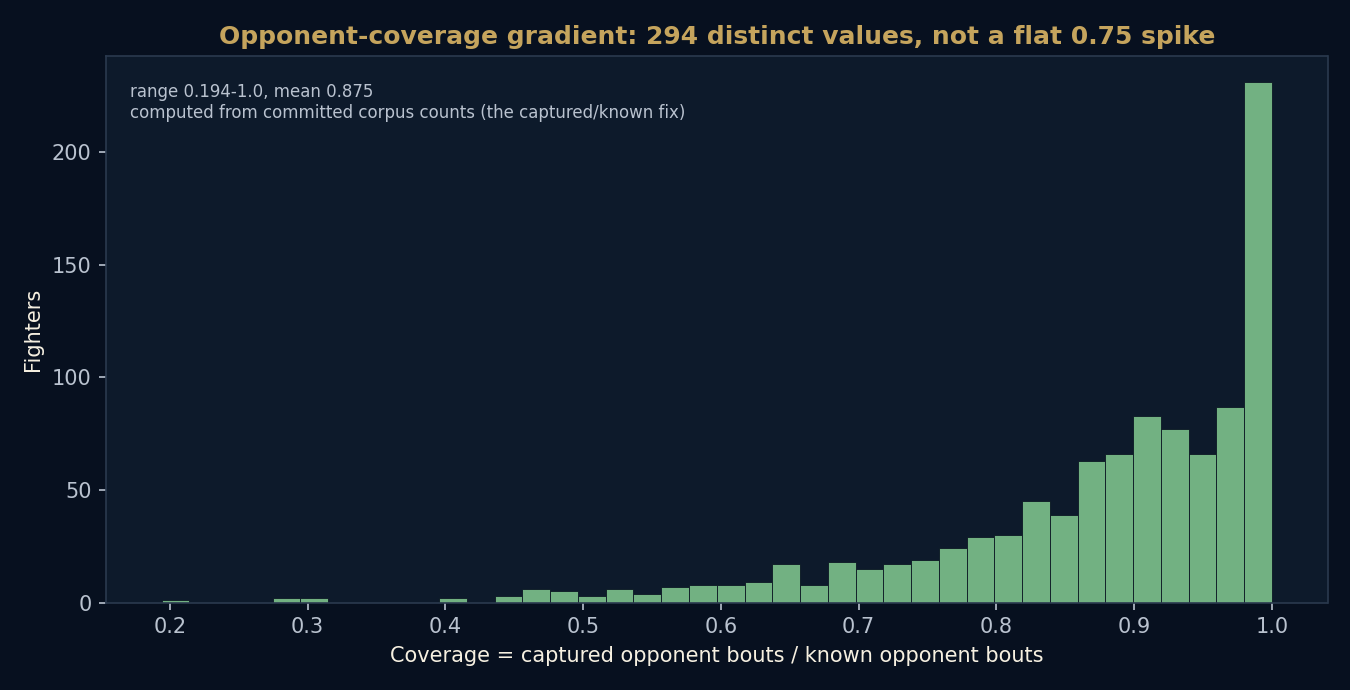
Across the public 1000 there are 294 distinct coverage values, running from about 0.19 to 1.0 with a mean near 0.875. Fully captured careers sit at 1.0; thinner records trail down the gradient. This is the figure the coverage discussion is built on, and it is the reason Data Confidence is lower for some early-era and resume-heavy cases. The model rates those cases conservatively and says so on the page, rather than adding an era-strength correction that would require an editorial judgement the data cannot support.
12. The honest trade-offs
Three costs are accepted openly. None is hidden in a footnote.
First, the determinism trade. The order-independent fit costs about 0.7 per cent of stage-1 calibration measured by log loss. The stage-1 self-validity gate therefore fails, returning a non-zero code, and that failure is accepted explicitly by a documented flag rather than silently swallowed. The release buys reproducibility and pays a small, stated amount of calibration for it.
Second, divisions are post-patched, not root-computed. v2 reproduces the live divisions by applying a committed correction inside the pipeline, exactly as the live site does. It does not compute each fighter's division cleanly from an era-aware weight-class derivation. That root-cause computation is deferred to a later release, and this paper does not imply the clean version exists yet.
Third, two joins were re-keyed for robustness. The sigma-prior join and the enrichment join were moved from matching on a display slug to matching on a stable fighter identifier, which is the correct key. These corrections are neutral against the live board, so they change no placement, but they are the right engineering and they remove a class of silent mismatch.
13. Validation and the regression sentinels
The audit rounds of section 5 are preventive; validation is the standing check that they hold. The release carries a suite of named sentinel cases, each one a defect that was found, fixed and then frozen as a test. The century-parse case, an impossible post-career date case, and an alias-resolution case for a great whose records were split across spellings are all in the suite, alongside a stable comparison set near the top of the board. A build that would move a sentinel, or move a top placement beyond a set threshold without an explicit sign-off, fails rather than ships. Validation also re-derives the public index from the underlying model score for every row, so the displayed number and the fitted number cannot drift apart unnoticed.
14. The version lineage
v2.0.0 did not arrive in one step, and the path is part of the evidence. The v1.2 line renamed the rank-driving number to the H&G All-Time Index and moved it onto a fixed 0 to 100 display, so a career index would stop reading like a head-to-head rating. The v1.2.3 line carried the accumulating data and identity corrections. v2.0.0 then made the fit itself deterministic and folded those corrections in, while holding the published order neutral against v1.2.3. Each step was scoped to do one kind of thing, so that a change in transparency, a change in data and a change in the fit were never entangled in a way that would make any one of them hard to audit.
15. What a careful reader should take away
v2.0.0 is a major release because it makes the rating fit fully deterministic and folds in the corrections gathered since v1.2.3, while leaving the published order neutral against v1.2.3. You can rebuild the board and check it. The placements near the top are firm; close ranks in thin-record regions should be read with the Data Confidence label beside them. The prior is one list, bounded in influence to four evidence units. The divisions are correct on the page but not yet computed from first principles. None of that is a reason to distrust the ranking. It is the set of conditions under which the ranking means what it says.
A formal version of this paper is available to download, and the plain-language companion explains the same ideas without the apparatus.
References
- Bradley, R. A. and Terry, M. E. (1952). Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika, 39(3/4), 324 to 345.
- Coulom, R. (2008). Whole-History Rating: a Bayesian rating system for players of time-varying strength. In Computers and Games 2008, Lecture Notes in Computer Science 5131, 113 to 124. Springer.
- Efron, B. and Morris, C. (1975). Data analysis using Stein's estimator and its generalizations. Journal of the American Statistical Association, 70(350), 311 to 319.
- Elo, A. E. (1978). The Rating of Chessplayers, Past and Present. Arco Publishing, New York.
- Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A. and Rubin, D. B. (2013). Bayesian Data Analysis, third edition. Chapman and Hall / CRC.
- International Boxing Research Organization (2019). All-time pound-for-pound ranking. Used as the bounded shrinkage reference.
- NIST (2015). Secure Hash Standard (SHS), FIPS Publication 180-4. National Institute of Standards and Technology.
- Comparator lists held for validation: The Ring magazine all-time pound-for-pound ranking; the Transnational Boxing Rankings Board; ESPN all-time ranking.